一、网络通信简介
现代的网络传输介质以以太网链路居多,完整的网络数据报结构大致如下。传输层及其以下的机制由操作系统内核提供,应用层由用户进程提供,应用程序对通讯数据的含义进行解释,而传输层及其以下处理通讯的细节,将数据从一台计算机通过一定的路径发送到另一台计算机。应用层数据通过协议栈发到网络上时,每层协议都要加上一个数据首部(header),称为封装(Encapsulation),如下图所示: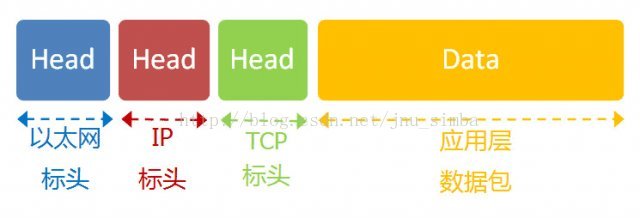
假设现在应用层协议为http,那么其中的Data 可以看作是一个http请求或者应答,Data包含真正的报头和请求正文。
二、HTTP 协议简介
HTTP 请求由三部分组成,分别是:请求行、消息报头、请求正文;HTTP 响应也是由三个部分组成,分别是:状态行、消息报头、响应正文,它们之间以CRLF 即 \r\n 分割,且报头与正文之间有一个空行。一个常规的HTTP请求如下所示:
POST /test.html HTTP/
Accept:image/gif,image/x-xbit
HOST:www.jnu.edu.cn
Content-Length:22
Connection:Keep-Alive
Cache-Control:no-cache
...具体的一些请求METHOD,请求头的含义,响应码的含义就不多说了,wikipedia都可以查得到。
三、Cookie
cookie主要分为session cookie 和 persistent cookie。
session cookie: 是一种临时的cookie,它记录了用户访问站点时的设置和偏好,关闭浏览器,会话cookie就被删除了。比如我们常见的Session ID
Examples of the names that some programming languages use when naming their cookie include JSESSIONID (JEE), PHPSESSID (PHP), and ASPSESSIONID (Microsoft ASP)
在某些wap站点会使用一种url重写的技术来进行会话跟踪,即每次HTTP交互,URL 后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。sid 出现在 url 中的情形有个安全隐患是,假设一个站点被引入了一个外部图片,打开这个站点会发起图片的get 请求,而 referer 就是受害站点的 url,由此泄露了 sid。
persistent cookie:存储在硬盘上(不管浏览器退出,或者电脑重启,持久cookie都存在),持久cookie有过期时间。
下面是典型的client-server交互过程:
client :
Cookie: name=value; name2=value2
server:
Set-Cookie: LSID=DQAAAK…Eaem_vYg; Path=/accounts; Expires=Wed, 13 Jan 2021 22:23:01 GMT; Secure; HttpOnly
Set-Cookie: HSID=AYQEVn….DKrdst; Domain=.foo.com; Path=/; Expires=Wed, 13 Jan 2021 22:23:01 GMT; HttpOnly
Set-Cookie: SSID=Ap4P….GTEq; Domain=foo.com; Path=/; Expires=Wed, 13 Jan 2021 22:23:01 GMT; Secure; HttpOnlycookie 无法跨浏览器存在。Domain 和 Path 决定浏览器在访问此站点某目录下的网页时cookie 才会被发送出去(domain 可以设置为父域,但不可设置为子域和外域)。Expires 确定cookie的过期时间,没有过期时间则为session cookie,有则是persistent cookie,过期时间是过去时间点则表示删除cookie。Secure 表示只有通过https 连接才会发送cookie。HttpOnly 表示只有通过http 访问才会发送cookie,比如在客户端执行js: document.cookie 是获取不到cookie的,如果只设置了 Secure 而未设置 httponly,那么还是可以通过 客户端 js 获取到 cookie。
需要注意的是设置 path 不能防止重要的cookie 被盗取,假设在同域下的b路径存在xss漏洞可以执行js,想盗取a 路径的cookie,只需在 b 路径用 iframe 方式加载 a 路径,获取 a 路径的cookie(iframe 加载的是同域页面,故 b路径的js 可以访问 iframe document 的属性),如下图所示:
前面讲了客户端的cookie 设置,那么服务端一般是如何利用cookie 呢?以Web.py 框架中的一小段代码示例如下:
'cookie_name': 'webpy_session_id' // 定义
self.session_id = web.cookies().get(cookie_name) // server 获取sessionId
self._setcookie(self.session_id) // server 设置Client 的cookie,Set-Cookie 头,即调用下面的函数
web.setcookie(cookie_name, session_id, expires=expires, domain=cookie_domain, httponly=httponly, secure=secure, path=cookie_path)
self.store[self.session_id] = dict(self._data) // server 端存储session_id 相关的用户数据即可以认为客户端发送过来的Cookie 头中的某个key-value,此 value 作为服务器端的一个索引,索引到的数据中存储着此用户相关的一系列数据,具体的存储方式可以是内存、数据库、文本等。当客户端的cookie 过期时,此时服务器却是不知道的,故服务器可能会设置一个过期时间,当距离客户端上一次使用session的时间超过这个失效时间时,服务器就可以认为客户端已经停止了活动,才会把这个session删除以节省存储空间。
四、URL的构成
url 即我们平时所说的链接,通过它可以找到唯一的资源,格式如下: <scheme>://<netloc><path>?<query>#<frag>
需要注意的是,frag 即我们口中的锚是不会传递到后端服务器的,它是一种前端行为,即定位到页面某个位置的功能。
现在常见的参数格式除了最原始的 /path/aa.html?a=1&b=2;还有 restful 的 /page/1/id/2011 即 传入的参数是 page=1&id=2011; 此外还有 rewrite,比如 /path/2015/a(a : 1--100)/b(b: 10--20) 对应后端的cgi 可能是 /path/c.cgi?p=a&q=b;一些 MVC 框架的 cgi 可能需要根据某个参数的值选择不同的逻辑分支,比如 a.cgi?_path=/gdata/6/data&id=5,映射到一个类;还有一种是参数直接跟在uri后面的,如 http://aa.qq.com/m/index/nav/type=bus&cond=3 , 可以理解为 /m/{module}/{action}/{query_list}, module 和 action 可以不断对请求进行路由,逐级分发到不同的模块,最终query_list是使用常规的webserver解析方式。
桌面应用程序也通过HTTP协议跟Web服务器交互, 桌面应用程序一般不会使用cookie, 而是把 "用户名+冒号+密码"用BASE64 编码的字符串放在http request 中的header Authorization 中发送给服务端, 这种方式叫HTTP基本认证(Basic Authentication),在浏览器里可以用 http://username:password@url 这种方式直接略过这个基本认证,对于某些漏洞来说,这也是个绕过姿势。
这里涉及到了HTTP 状态码 401 与 403的不同之处。401 表示没有认证,而403 表示没有授权,认证的目的是为了认出用户是谁,而授权的目的是为了决定用户能够做什么。
401 的限制一般可以在某个目录下的 .htaccess 文件(apache)写上
AuthName "frank share web"
AuthType Basic
AuthUserFile /var/www/test/.htpasswd
require valid-user且 httpd.conf 中对于此目录中的设置中 加上 AllowOverride AuthConfig 表示进行身份验证。
有时候访问出现403 forbidden ,有种原因是 apache 设置的user,即运行httpd的user 是nobody(假设),对你想要访问的目
录/文件 没有读或者执行的权限,所以server 没办法读取执行文件,故 禁止访问。还有种情况是配置文件写明 deny xxx,禁止某些来源ip 访问,或者禁止访问某些目录、某种后缀的文件。比如我们直接访问某个目录,此目录下有 index.html 之类的默认文件,则访问到它,如果没有则正常是提示access forbidden,若此时把此目录下的文件都列出来了,就是个目录列举漏洞了。
五、四种常见的 POST 提交数据方式
1.application/x-www-form-urlencoded
这应该是最常见的 POST 提交数据的方式了。浏览器的原生 form 表单,如果不设置 enctype 属性,那么最终就会以 application/x-www-form-urlencoded 方式提交数据,请求类似于下面这样(无关的请求头在本文中都省略掉了):
POST http://www.example.com HTTP/1.1
Content-Type: application/x-www-form-urlencoded;charset=utf-8
title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=32.multipart/form-data
这又是一个常见的 POST 数据提交的方式。我们使用表单上传文件时,必须让 form 的 enctyped 等于这个值。直接来看一个请求示例:
POST http://www.example.com HTTP/1.1
Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="text"
title
------WebKitFormBoundaryrGKCBY7qhFd3TrwA
Content-Disposition: form-data; name="file"; filename="chrome.png"
Content-Type: image/png
... content of chrome.png ...
------WebKitFormBoundaryrGKCBY7qhFd3TrwA--这个例子稍微复杂点。首先生成了一个 boundary 用于分割不同的字段,为了避免与正文内容重复,boundary 很长很复杂。然后 Content-Type 里指明了数据是以 mutipart/form-data 来编码,本次请求的 boundary 是什么内容。消息主体里按照字段个数又分为多个结构类似的部分,每部分都是以 --boundary 开始,紧接着内容描述信息,然后是回车,最后是字段具体内容(文本或二进制)。如果传输的是文件,还要包含文件名和文件类型信息,消息主体最后以 --boundary-- 标示结束。 注意: post body 里面的 boundary 前缀 - 长度比 content-type 里的多 2个;如 post body 里面的"title" 文本位置也是xss or sql注入等 payload 可以 append/replace 的地方;甚至 filename 的值可以填充xss/sql 用例,如果网站直接把上传后的文件名显示出来,也存在xss 漏洞,或者把 filename 没有过滤就带入 sql 查询也存在 sql 注入漏洞。
假设同时上传两个文件,则格式略有区别,如下:
Content-type: multipart/form-data, boundary=AaB03x
--AaB03x
content-disposition: form-data; name="field1"
Joe Blow
--AaB03x
content-disposition: form-data; name="pics"
Content-type: multipart/mixed, boundary=BbC04y
--BbC04y
Content-disposition: attachment; filename="file1.txt"
Content-Type: text/plain
... contents of file1.txt ...
--BbC04y
Content-disposition: attachment; filename="file2.gif"
Content-type: image/gif
Content-Transfer-Encoding: binary
...contents of file2.gif...
--BbC04y--
--AaB03x--与上传文件相关的下载文件 Content-Type: application/octet-stream
Hence: Content-Type: application/octet-stream
Content-Disposition: attachment; filename="picture.png"
Means "I don't know what the hell this is. Please save it as a file, preferably named picture.png".
Content-Type: image/png
Content-Disposition: attachment; filename="picture.png"
Means "This is a PNG image. Please save it as a file, preferably named picture.png".
Content-Type: image/png
Content-Disposition: inline; filename="picture.png"
Means "This is a PNG image. Please display it unless you don't know how to display PNG images. Otherwise, or if the user chooses to save it, we recommend the name picture.png for the file you save it as".
Of those browsers that recognise inline some would always use it, while others would use it if the user had selected "save link as" but not if they'd selected "save" while viewing (or at least IE used to be like that, it may have changed some years ago).
3.application/json
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。
POST http://www.example.com HTTP/1.1
Content-Type: application/json;charset=utf-8
{"title":"test","sub":[1,2,3]}4.text/xml
XML-RPC 协议简单、功能够用,各种语言的实现都有。
POST http://www.example.com HTTP/1.1
Content-Type: text/xml
<?xml version="1.0"?>
<methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value><i4>41</i4></value>
</param>
</params>
</methodCall>php 在处理不同 post数据方式时的不同点:
Content-Type 仅在取值为application/x-www-data-urlencoded 和multipart/form-data 两种情况下,PHP才会将http请求数据包中相应的数据 urldecode 后以 keyvalue 形式 填入全局变量$_POST
只有Content-Type 为multipart/form-data 的时候,PHP不会将http请求数据包中的相应数据填入php://input,否则其它情况都会。填入的长度,由Content-Length 指定。
只有Content-Type为application/x-www-data-urlencoded 时,php://input 数据才跟$_POST 数据相“一致”。也就是说其他情况下 php://input 是原始的字符串,需要经过解析才能进一步使用,比如 application/json (调用 json_decode)。
php://input 数据总是跟 $HTTP_RAW_POST_DATA 相同,但是php://input 比$HTTP_RAW_POST_DATA 更奏效,且不需要特殊设置php.ini(需要设置php.ini中的always_populate_raw_post_data 值为On,PHP才会把POST 数据填入变量 $http_raw_post_data )
PHP会将PATH字段的query_path 部分,urldecode 后填入全局变量$_GET。通常情况下,GET方法提交的http请求,body 为空。
六、Http 协议的chunked编码
在 HTTP/1.1 协议中增加了如下关于 chunk 的内容:
Faster response for dynamically-generated pages, by supporting chunked encoding, which allows a response to be sent before its total length is known.
对于支持 HTTP/1.1 协议的客户端,要求能够处理以 chunked 形式组织的 response ,具体如下:
【Chunked Transfer-Encoding】
如果服务器想要在不知道 response 总体长度的情况下进行应答(就像使 long script output 那样),其需要使用简单的 chunked transfer-encoding 方式,即将完整的 response 拆分成更小的 chunk 后连续发送。你可以很容易辨认出这种类型的 response ,因为其包含了 Transfer-Encoding: chunked 头。所有支持 HTTP/1.1 协议的客户端都必须能够接收并处理 chunked 消息。
一条 chunked 消息由一组 chunk 构成,随后是由 "0" 构成的行,然后是多个可选的 footer ,最后是空行。每一块 chunk 有两部分构成:
- 用于表示 chunk 数据长度的、以十六进制表示的、独占一行的数值。其后可能还有可以忽略的分号和额外参数(目前这些内容都未成为标准),以及结束标志 CRLF 。
- 数据本身,以 CRLF 结尾。
上述 chunked response 样子如下:
HTTP/1.1 200 OK
Date: Fri, 31 Dec 1999 23:59:59 GMT
Content-Type: text/plain
Transfer-Encoding: chunked
1a; ignore-stuff-here
abcdefghijklmnopqrstuvwxyz
10
1234567890abcdef
0
some-footer: some-value
another-footer: another-value
[blank line here]需要注意的是,最后一个 footer 后面还需要有空行。当前文本数据的长度是 42 个字节(十六机制 1a + 10),而数据本身为 abcdefghijklmnopqrstuvwxyz1234567890abcdef 。而 footer 要以 header 来看待,就好像它们是直接被放在 response 头部一样。
chunk 数据可以包含任意二进制数据,并且很可能包含了很大的数据。表明 chunk 长度的 size 值很好被直接使用,但你需要确保程序中正确的忽略掉它们。footer 也很少被使用,但是它们会被用于 checksum 或数字签名的场景中。
作为对比,下面提供了一个等价于上面 response 的另一个例子,但是没有采用 chunked 编码形式:
HTTP/1.1 200 OK
Date: Fri, 31 Dec 1999 23:59:59 GMT
Content-Type: text/plain
Content-Length: 42
some-footer: some-value
another-footer: another-value
abcdefghijklmnopqrstuvwxyz1234567890abcdef而对于支持 HTTP/1.1 协议的服务器,同样需要能够接受以 chunked 数据格式发送来的 request,这种request 有时候能作为绕 waf 的手段。
Just as HTTP 1.1 clients must accept chunked responses, servers must accept chunked requests (an unlikely scenario, but possible). Servers aren't required to generate chunked messages; they just have to be able to receive them.